Sản Phẩm Bán Chạy

Nâng cấp tài khoản Gemini Advanced
99,000 VNĐ

Nâng cấp Office 365 Chính Hãng
399,000 VNĐ

Nâng cấp tài khoản Quizizz Super chính chủ
799,000 VNĐ

Google One chính chủ Giá Siêu Hời
259,000 VNĐ

Adobe Photoshop Bản Quyền Full App Giá Rẻ
899,000 VNĐ

Nâng cấp Canva Pro giá rẻ
199,000 VNĐ

Nâng cấp Google One chính chủ Giá Siêu Rẻ
259,000 VNĐ

Tài khoản Zoom Pro Chính Chủ Giá Rẻ
199,000 VNĐ

Nâng cấp Coursera PLus chính chủ
399,000 VNĐ

Nâng cấp tài khoản Capture One chính hãng
350,000 VNĐ

Tài khoản CapCut Pro bản quyền chính hãng
399,000 VNĐ

Key Windows 10/11 Pro bản quyền
599,000 VNĐ

Nâng Cấp Tài Khoản Netflix Giá Rẻ
359,000 VNĐ

Tài Khoản ChatGPT Plus (GPT-4)
199,000 VNĐ

Nâng Cấp Tài khoản Freepik Premium
599,900 VNĐ

Trọn Bộ Autodesk All App Giá Rẻ
1,499,000 VNĐ

YouTube Premium Nâng cấp TK Chính Chủ
199,000 VNĐ

Nâng cấp Duolingo Super
299,000 VNĐ
Top mô hình AI 2026: Phân tích Claude Opus 4.6, GPT-5.4 và Gemini 3.1 Pro
Bài viết phân tích chi tiết cuộc cạnh tranh giữa Claude Opus 4.6, GPT-5.4 và Gemini 3.1 Pro dựa trên các benchmark mới nhất tháng 4/2026. Không chỉ dừng ở con số, nội dung đi sâu vào điểm mạnh, điểm yếu của từng mô hình trong coding, reasoning, đa nhiệm và chi phí triển khai.
Nội dung

Tháng 4/2026 có thể xem là một cột mốc đặc biệt trong lịch sử phát triển trí tuệ nhân tạo khi ba mô hình hàng đầu thế giới: Claude Opus 4.6, GPT-5.4 và Gemini 3.1 Pro cùng đạt đến một ngưỡng hiệu năng mà trước đây chỉ tồn tại trong giả thuyết. Nếu như ở các giai đoạn trước, thị trường AI thường chứng kiến một “người dẫn đầu rõ rệt”, thì ở thời điểm hiện tại, bức tranh đã trở nên phức tạp hơn rất nhiều: khoảng cách giữa các mô hình thu hẹp đến mức khó phân định thắng thua tuyệt đối, trong khi sự khác biệt về khả năng lại thể hiện rõ ràng hơn bao giờ hết khi đi vào từng loại nhiệm vụ cụ thể.
Sự thay đổi này không chỉ mang ý nghĩa về mặt công nghệ mà còn tác động trực tiếp đến cách doanh nghiệp, lập trình viên và người dùng phổ thông tiếp cận AI. Thay vì đặt câu hỏi “mô hình nào tốt nhất?”, chúng ta buộc phải chuyển sang câu hỏi thực tế hơn: “mô hình nào phù hợp nhất cho nhu cầu cụ thể của mình?”. Đây là một bước chuyển tư duy quan trọng, phản ánh sự trưởng thành của toàn bộ hệ sinh thái AI.
Bài viết này sẽ phân tích sâu các benchmark mới nhất, bóc tách điểm mạnh điểm yếu của từng mô hình, đồng thời đưa ra góc nhìn chiến lược về cách lựa chọn và sử dụng AI trong bối cảnh cạnh tranh khốc liệt hiện nay.
Mua Phần Mềm Bản Quyền Chính Hãng Giá Rẻ
1. Bức tranh tổng thể: Khi không còn “kẻ thống trị”
Các bảng xếp hạng AI tháng 4/2026 cho thấy một sự thay đổi mang tính bước ngoặt: không còn mô hình nào vượt trội tuyệt đối. Claude Opus 4.6, Gemini 3.1 Pro và GPT-5.4 đều đạt mức hiệu năng rất cao, với khoảng cách điểm số trong nhiều benchmark chỉ khoảng 1–3%. Điều này cho thấy cuộc đua đã bước sang giai đoạn “bão hòa về chất lượng cơ bản” và chuyển sang cạnh tranh về chiều sâu năng lực.
Tuy nhiên, sự cân bằng này không có nghĩa là các mô hình trở nên giống nhau. Ngược lại, mỗi mô hình đang phát triển theo một hướng riêng biệt. Anthropic tập trung vào độ an toàn, tính nhất quán và reasoning có kiểm soát, giúp mô hình đưa ra các câu trả lời logic và ít sai lệch. OpenAI với GPT-5.4 theo đuổi chiến lược đa dụng, tối ưu để phục vụ nhiều loại tác vụ trong cùng một hệ sinh thái. Trong khi đó, Google DeepMind đẩy mạnh khả năng suy luận tổng quát và tối ưu hiệu năng trên chi phí, giúp Gemini nổi bật trong các bài toán phức tạp.
Sự thay đổi quan trọng nhất nằm ở cách người dùng tiếp cận AI. Nếu trước đây mục tiêu là chọn “model tốt nhất”, thì hiện tại, trọng tâm là chọn “model phù hợp nhất”. Một mô hình có thể không đứng đầu tổng thể nhưng lại vượt trội trong một tác vụ cụ thể như coding, phân tích dữ liệu hay xây dựng agent tự động. Điều này khiến việc lựa chọn AI giống như thiết kế một hệ thống công cụ, nơi mỗi thành phần có vai trò riêng.

Ở góc độ thị trường, việc không có “kẻ thống trị” cũng mang lại lợi ích lớn: thúc đẩy cạnh tranh, giảm phụ thuộc vào một nền tảng duy nhất và mở ra xu hướng kết hợp nhiều mô hình. Đây chính là nền tảng cho các hệ thống AI lai (hybrid AI), vốn đang trở thành tiêu chuẩn mới trong các doanh nghiệp công nghệ.
2. Benchmark: Những con số và ý nghĩa phía sau
Các benchmark hiện đại như MMLU, GPQA, SWE-bench, MMMU hay ARC-AGI-2 đã tiến xa hơn việc kiểm tra kiến thức đơn thuần. Chúng được thiết kế để đánh giá khả năng suy luận, lập kế hoạch nhiều bước và thích nghi với tình huống mới.
Trong SWE-benchn (benchmark gần với môi trường lập trình thực tế nhất), Claude Opus 4.6 thường dẫn đầu. Điểm số cao ở đây không chỉ phản ánh khả năng viết code mà còn cho thấy năng lực hiểu cấu trúc hệ thống, dependencies và logic nghiệp vụ. Đây là loại năng lực rất khó đạt được nếu mô hình chỉ dựa vào pattern học được.
Ở chiều ngược lại, các benchmark như GPQA Diamond hay ARC-AGI-2 lại yêu cầu reasoning ở mức cao, nơi Gemini 3.1 Pro thường chiếm ưu thế. Những bài test này cố tình loại bỏ khả năng “học thuộc”, buộc mô hình phải xây dựng lập luận từ đầu, qua đó phản ánh khả năng tổng quát hóa thực sự.
Trong khi đó, GPT-5.4 không phải lúc nào cũng dẫn đầu từng benchmark nhưng lại duy trì hiệu năng cao và ổn định trên hầu hết các bài test. Điều này cho thấy một định hướng rõ ràng: tối ưu tính đa dụng và độ tin cậy thay vì tập trung vào một vài chỉ số riêng lẻ.
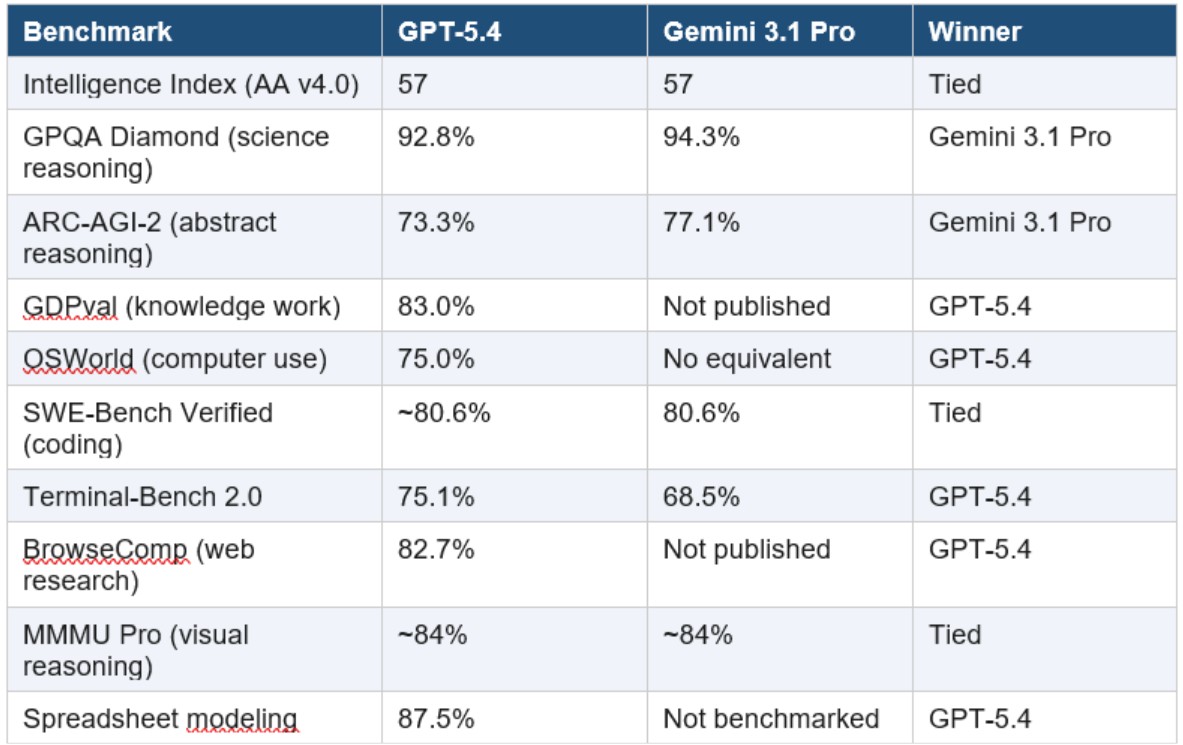
Tuy nhiên, cần nhìn nhận benchmark một cách thực tế. Chúng không đo được nhiều yếu tố quan trọng như chi phí vận hành, độ trễ, khả năng tích hợp hay hiệu suất trong workflow dài hạn. Ngoài ra, một số benchmark có thể bị “tối ưu hóa quá mức”, khiến điểm số cao nhưng không phản ánh đúng trải nghiệm thực tế. Vì vậy, benchmark nên được xem là công cụ định hướng ban đầu, còn quyết định cuối cùng cần dựa trên thử nghiệm trong môi trường thực.
3. Lợi thế của Claude
Trong lĩnh vực lập trình, Claude Opus 4.6 nổi bật nhờ khả năng hiểu sâu hệ thống thay vì chỉ viết code đúng cú pháp. Đây là yếu tố tạo nên sự khác biệt lớn khi chuyển từ các bài test đơn giản sang môi trường doanh nghiệp thực tế.
Claude có thể làm việc với codebase lớn, đọc hiểu nhiều module và xác định lỗi nằm sâu trong hệ thống. Quan trọng hơn, nó có khả năng đề xuất giải pháp mang tính hệ thống, đảm bảo việc sửa lỗi không làm ảnh hưởng đến các phần khác của chương trình. Điều này đặc biệt quan trọng trong các hệ thống phức tạp với nhiều dependency.
Khả năng debug của Claude cũng mang tính “giải thích” cao. Thay vì chỉ đưa ra đoạn code sửa lỗi, nó thường phân tích nguyên nhân, giải thích vì sao lỗi xảy ra và đề xuất cách khắc phục kèm reasoning rõ ràng. Điều này giúp lập trình viên không chỉ sửa lỗi mà còn hiểu sâu hơn về hệ thống của mình.
Ngoài ra, Claude hoạt động rất hiệu quả trong các workflow agent nhiều bước. Trong các hệ thống hiện đại, AI không chỉ trả lời mà còn thực hiện chuỗi hành động như đọc file, chỉnh sửa code, chạy test và triển khai. Khả năng giữ context và mục tiêu dài hạn giúp Claude giảm lỗi tích lũy trong các chuỗi tác vụ này.
Dù vậy, mỗi mô hình vẫn có thế mạnh riêng. Gemini 3.1 Pro có thể vượt trội trong các bài toán thuật toán hoặc reasoning sâu, còn GPT-5.4 lại mạnh về tích hợp hệ sinh thái và triển khai nhanh trong nhiều môi trường khác nhau.
Tổng thể, lợi thế của Claude trong coding không chỉ nằm ở khả năng viết code, mà ở việc nó hiểu cách phần mềm được xây dựng và vận hành trong thực tế. Đây là yếu tố khiến nó trở thành lựa chọn hàng đầu cho các hệ thống kỹ thuật phức tạp và các ứng dụng AI agent trong doanh nghiệp.
4. Gemini vượt lên
Ở chiều ngược lại với coding, Gemini 3.1 Pro nổi bật nhờ khả năng suy luận sâu và tổng quát hóa. Trong các benchmark như GPQA hay ARC-AGI-2, Gemini thường cho thấy mức độ chính xác cao và đặc biệt ổn định trong những bài toán chưa từng xuất hiện trong dữ liệu huấn luyện.
Điểm mạnh của Gemini không chỉ nằm ở việc đưa ra đáp án đúng, mà ở cách nó xây dựng lập luận. Các bước reasoning thường rõ ràng, có tính logic cao và ít phụ thuộc vào “pattern quen thuộc”. Điều này rất quan trọng trong các lĩnh vực như nghiên cứu khoa học, phân tích dữ liệu phức tạp hoặc lập kế hoạch chiến lược, nơi câu trả lời cần có tính giải thích và khả năng kiểm chứng.
Khả năng tổng quát hóa giúp Gemini xử lý tốt các tình huống mới, nơi không có sẵn dữ liệu tham chiếu. Đây chính là yếu tố then chốt để tiến gần hơn đến mục tiêu trí tuệ nhân tạo tổng quát (AGI), nơi mô hình có thể thích nghi với nhiều loại bài toán khác nhau mà không cần huấn luyện riêng biệt.
Tuy nhiên, lợi thế này cũng đi kèm một số đánh đổi, như đôi khi chi phí tính toán cao hơn trong các bài toán phức tạp. Dù vậy, trong các ứng dụng đòi hỏi độ chính xác và chiều sâu suy luận, Gemini vẫn là lựa chọn nổi bật.
5. Sức mạnh của GPT-5.4
Dù không luôn dẫn đầu từng benchmark riêng lẻ, GPT-5.4 lại là lựa chọn phổ biến nhất trong nhiều ứng dụng thực tế. Lý do nằm ở sự cân bằng giữa hiệu năng, độ ổn định và khả năng tích hợp trong hệ sinh thái rộng.

GPT-5.4 có thể xử lý tốt nhiều loại nhiệm vụ khác nhau như viết nội dung, lập trình, phân tích dữ liệu, hỗ trợ khách hàng hay tự động hóa quy trình mà không cần tinh chỉnh quá nhiều. Điều này giúp doanh nghiệp giảm đáng kể chi phí triển khai và thời gian phát triển hệ thống.
Một lợi thế quan trọng khác là hệ sinh thái xung quanh OpenAI. Từ API, plugin cho đến các công cụ hỗ trợ và nền tảng tích hợp, GPT-5.4 dễ dàng được đưa vào các workflow sẵn có. Đây là yếu tố mang tính thực dụng rất cao, đặc biệt với các tổ chức cần triển khai nhanh và ổn định.
6. Context dài và xử lý đa phương thức
Một xu hướng rõ ràng trong năm 2026 là việc mở rộng context window. Cả Claude Opus 4.6, Gemini 3.1 Pro và GPT-5.4 đều hỗ trợ xử lý hàng trăm nghìn đến hàng triệu token, cho phép làm việc với tài liệu dài, video, hình ảnh và dữ liệu đa phương thức.
Tuy nhiên, sự khác biệt nằm ở cách các mô hình tận dụng context. Claude nổi bật trong việc đọc hiểu tài liệu dài và trích xuất thông tin chính xác, rất phù hợp với các tác vụ phân tích văn bản lớn. Gemini lại thể hiện khả năng duy trì tính nhất quán (coherence) tốt khi xử lý chuỗi dữ liệu dài, giúp giảm hiện tượng “quên ngữ cảnh”.
Trong khi đó, GPT-5.4 tận dụng context dài thông qua khả năng tích hợp với công cụ bên ngoài, cho phép kết hợp giữa AI và hệ thống dữ liệu thực tế. Điều này giúp mở rộng phạm vi ứng dụng từ xử lý nội dung sang điều phối workflow phức tạp.
Mua Phần Mềm Bản Quyền Chính Hãng Giá Rẻ
7. Chi phí và hiệu quả triển khai
Khi AI được triển khai ở quy mô lớn, chi phí trở thành yếu tố quyết định không kém gì hiệu năng. Gemini 3.1 Pro thường được đánh giá cao về tỷ lệ hiệu năng/giá thành, khiến nó trở thành lựa chọn hấp dẫn cho startup hoặc các ứng dụng cần tối ưu ngân sách.
Claude Opus 4.6 có chi phí cao hơn nhưng đổi lại là chất lượng vượt trội trong các tác vụ phức tạp, đặc biệt là coding và agent workflow. Điều này phù hợp với các doanh nghiệp cần độ chính xác cao và sẵn sàng đầu tư cho hiệu năng.
GPT-5.4 nằm ở vị trí trung gian, cung cấp sự cân bằng giữa chi phí và hiệu năng. Nhờ hệ sinh thái mạnh, tổng chi phí triển khai thực tế của GPT-5.4 trong nhiều trường hợp có thể thấp hơn so với việc chỉ nhìn vào giá API.
Tổng thể, lựa chọn mô hình không chỉ là bài toán kỹ thuật mà còn là bài toán kinh tế. Một mô hình “tốt hơn” chưa chắc là lựa chọn tối ưu nếu chi phí không phù hợp với quy mô và mục tiêu của hệ thống.
Cuộc cạnh tranh giữa Claude Opus 4.6, GPT-5.4 và Gemini 3.1 Pro cho thấy AI đã bước sang một giai đoạn trưởng thành, nơi không còn một mô hình thống trị tuyệt đối. Thay vào đó là sự đa dạng và chuyên môn hóa, buộc người dùng phải hiểu rõ nhu cầu của mình để lựa chọn công cụ phù hợp.
Công Ty TNHH Phần Mềm SADESIGN
Mã số thuế: 0110083217





















Sản phẩm nổi bật

Nâng Cấp Tài Khoản ChatGPT 4.0 Plus
199,000

Nâng cấp Google One chính chủ Giá Siêu Rẻ
259,000

Adobe Photoshop Bản Quyền Chính Hãng
899,000

Canva Pro Chính Hãng Giá Rẻ
199,000

Nâng cấp Tài khoản Zoom Pro Chính Chủ Giá Rẻ
199,000

Tài khoản CapCut Pro bản quyền chính hãng
399,000

One Drive 1TB + Office 365
399,000

Nâng Cấp YouTube Premium Chính Chủ
199,000
Sản Phẩm Bán Chạy
Nâng cấp tài khoản Gemini Advanced
99,000 VNĐ
Nâng cấp Office 365 Chính Hãng
399,000 VNĐ
Nâng cấp tài khoản Quizizz Super chính chủ
799,000 VNĐ
Google One chính chủ Giá Siêu Hời
259,000 VNĐ
Adobe Photoshop Bản Quyền Full App Giá Rẻ
899,000 VNĐ
Nâng cấp Canva Pro giá rẻ
199,000 VNĐ
Nâng cấp Google One chính chủ Giá Siêu Rẻ
259,000 VNĐ
Tài khoản Zoom Pro Chính Chủ Giá Rẻ
199,000 VNĐ
Nâng cấp Coursera PLus chính chủ
399,000 VNĐ
Nâng cấp tài khoản Capture One chính hãng
350,000 VNĐ
Tài khoản CapCut Pro bản quyền chính hãng
399,000 VNĐ
Key Windows 10/11 Pro bản quyền
599,000 VNĐ
Nâng Cấp Tài Khoản Netflix Giá Rẻ
359,000 VNĐ
Tài Khoản ChatGPT Plus (GPT-4)
199,000 VNĐ
Nâng Cấp Tài khoản Freepik Premium
599,900 VNĐ
Trọn Bộ Autodesk All App Giá Rẻ
1,499,000 VNĐ
YouTube Premium Nâng cấp TK Chính Chủ
199,000 VNĐ
Nâng cấp Duolingo Super
299,000 VNĐ




